
Contenus de la page
Généralités
L’objectif de ce cours est de résoudre le problème de détection de tag Aruco embarqué sur un Raspberry Pi. À travers ce cours nous verrons trois notions : le traitement d’image (classique et par IA) et la manière dont nous pouvons l’utiliser (OpenCV), les tag Aruco ainsi que le principe des API.
Diapositives du cours
Présentation du cours et prérequis
- Mardi 15 février : Présentation du cours, introduction au traitement d’image
- Mardi 15 mars : Introduction à OpenCV 💻
- Mardi 22 mars : Détection de tag Aruco 💻
- Mardi 29 mars : Embarquement sur Raspberry Pi et API 💻
Les cours 2, 3 et 4 nécessitent d’avoir un environnement Python 3.x installé. Les cours 3 et 4 seront plus simple sous Linux.
Programme du cours
- Présentation du cours (30 minutes)
- Traitement d’images classique (45 minutes)
- Traitement d’images par intelligence artificielle (45 minutes)
Améliorer l’aspect visuel de vos images
Le traitement d’images désigne l’ensemble des techniques permettant de modifier une image, souvent dans le but de l’améliorer. Par exemple, il est possible de la rendre plus lumineuse ou plus nette. Cette discipline se situe à la croisée des mathématiques appliquées et de l’informatique, c’est pourquoi nous nous intéresserons désormais à la définition d’une image dans ces deux domaines.
Représentation d’une image
Qu’est qu’une image ? Cette question simple admet en réalité plusieurs réponses, plus ou moins techniques selon le domaine étudié. Commençons par donner la réponse qui vient naturellement à la majorité d’entre nous : une image est une représentation visuelle de quelque chose ou de quelqu’un.

L’image vue comme une fonction mathématique
En mathématiques, une image est une fonction. Cette fonction quantifie l’intensité lumineuse de n’importe quel point dans l’image. Dans une image en noir et blanc, l’intensité est le niveau de gris : plus un point est sombre, plus son niveau de gris est fiable.
Dans le cas d’une image en couleurs, l’intensité d’un point désigne sa couleur. Celle-ci peut être perçue comme un mélange de trois couleurs primaires (rouge, vert, bleu). Ainsi, une image ne correspond non plus à une seule fonction, mais à trois : nous associons à chaque point son intensité de rouge, de vert et de bleu. Ces trois valeurs sont stockées dans un vecteur colonne de taille trois, de sorte que l’image puisse être représentée comme une fonction vectorielle.
En traitement d’image, il n’est pas possible de se contenter de définir une image comme « quelque chose que l’on voit et qui représente une information ». En effet, comme nous allons le voir, la modification d’une image fait intervenir des opérations mathématiques. Celles-ci sont formulées de manière beaucoup plus intelligible et précise si l’on considère l’objet auquel elles s’appliquent.
L’image numérique
Le traitement d’images fait intervenir des outils non seulement issus des mathématiques appliquées, mais aussi de l’informatique. La définition mathématique d’une image ne convient pas à un ordinateur : des restrictions doivent être imposées sur les ensembles de définition et d’arrivée de la fonction.
Dans notre définition mathématique, l’abscisse, l’ordonnée et l’intensité d’un point donné de l’image peuvent prendre n’importe quelle valeur réelle. C’est pourquoi nous parlons de modèle continu ou d’image analogique.
Une image en informatique est ainsi une discrétisation (ou numérisation) de notre modèle continu : nous l’appelons image numérique. Cette discrétisation se fait à la fois sur l’ensemble de définition de la fonction image (échantillonnage) et sur son ensemble d’arrivée (quantification)
Une image numérique est une image échantillonnée et quantifiée. La définition formelle d’une image numérique en noir et blanc est donc la suivante
\(I : \{0,1,…,w-1\} \times \{0,1,…,h-1\} \rightarrow \{0,1,…,255\}\)
L’ordinateur traite une image comme une matrice d’entiers de taille \(h \times w\) contenant les niveaux de gris de ses pixels.
Notons que si cette représentation est la plus courante pour afficher une image, la lire ou l’écrire dans un fichier, nous travaillerons généralement sur des images sans quantification et nous n’appliquerons la quantification qu’à la fin.
Premiers traitements d’images
Nous abordons ici les techniques de traitement d’images basées sur la modification d’histogrammes. Ces méthodes font partie de la classe des traitements dits ponctuels : la valeur de chaque pixel est corrigée, et ce, indépendamment des autres pixels.
Manipulation d’histogrammes
L’histogramme d’une image numérique est une courbe statistique représentant la répartition de ses pixels selon leur intensité. Pour une image en noir et blanc, il indique en abscisse le niveau de gris (entier entre 0 et 255) et en ordonnée, le nombre de pixels ayant cette valeur.
Lorsque l’histogramme est normalisé, il indique en ordonnée la probabilité \(p_i\) de trouver un pixel de niveau de gris \(i\) dans l’image. L’intensité d’un pixel est alors vue comme une variable aléatoire discrète. Un histogramme cumulé normalisé calcule le pourcentage de pixels ayant une valeur inférieure à un niveau de gris donné.
import cv2
import matplotlib.pyplot as plt
# load simba image
simba = cv2.imread('data/simba.png', cv2.IMREAD_GRAYSCALE)
# compute hist of simba.png
hist = cv2.calcHist([simba], [0], None, [256], [0, 256])
f, plot = plt.subplots(1, 2)
plot[0].imshow(simba, cmap='gray')
plot[1].plot(hist)
plt.show()
Il s’agit d’un outil très important en traitement d’images, car sa modification permet d’ajuster la dynamique des niveaux de gris ou des couleurs dans une image afin de la rendre plus agréable visuellement. Grossièrement, à gauche se situent les pixels noirs et à droite les pixels blancs.
Une première application consiste à corriger la luminosité ou exposition, de l’image. Analysons la forme des histogrammes pour des images dont l’exposition est mauvaise

Vous pouvez constater que pour l’image trop sombre, ou sous-exposée, la majorité des pixels se situent dans la partie gauche de l’histogramme, vers les valeurs de niveaux de gris faibles.
En revanche, l’histogramme associé à l’image dont l’exposition est relativement bonne présente une répartition des pixels sur tout l’intervalle. Ainsi pour corriger les défauts liés à l’exposition d’une image, il suffit d’étirer son histogramme.
Cette transformation se fait simplement à l’aide de la règle de trois : la valeur de chaque pixel est remplacée par le résultat de la formule ci-dessous.
\(I'(x,y) = \frac{255 \times (I(x,y) – I_{min})}{I_{max}-I_{min}}\)
La deuxième application courante concerne l’amélioration du contraste de l’image.
Le contraste caractérise la répartition de lumière dans une image : plus une image est contrastée, plus la différence de luminosité entre ses zones claires et sombres est importante. En général, une image peu contrastée est terne, tandis qu’une image trop contrastée est visuellement « agressive ». Dans les deux cas, l’image manque de clarté car certains de ses détails seront peu, voir pas du tout, visibles.
L’égalisation d’histogrammes est une technique simple permettant de réajuster le contraste d’une image et ainsi de lui redonner du peps ou de l’adoucir. Pour comprendre de manière intuitive le fonctionnement de ce traitement, étudions l’allure de l’histogramme pour des images peu ou trop contrastées.


Comme nous pouvons le constater, les pixels des images dont le contraste est mauvais se répartissent dans tout l’intervalle disponible, donc un étirement d’histogramme n’améliora rien, mais pas de manière équitable.
L’objectif est donc d’harmoniser la distribution des niveaux de gris de l’image, de sorte que chaque niveau de l’histogramme contienne idéalement le même nombre de pixels. Concrètement, nous essyons d’aplatir au maximum l’histogramme original.
Pour cela nous calculons d’abord l’histogramme cumulé normalisé de l’image, puis nous ajustons la valeurs de chaque pixel en utilisant la formule mathématique suivante :
\(I'(x,y) = 255 \times \sum \limits_{i=0}^{I(x,y)} p_i\)
où \(p_i\) désigne la probabilité qu’un pixel de l’image initiale soit d’intensité \(i\).
L’égalisation d’histogramme se fait avec la fonction cv2.equalizeHist du module OpenCV en python.

Élimination du bruit
La qualité d’une photo peut également être dégradée par du bruit numérique, c’est-à-dire par l’apparition aléatoire de grains superflus. Il s’agit d’un phénomène courant en photographie numérique, dû à un mauvais réglage de la sensibilité des capteurs de l’appareil photo, ou à une limitation de leurs capacités.
Le bruit peut être vu comme une image constituée de pixels dont les intensités ont été déterminées de manière aléatoire.
Une image étant définie soit comme une fonction, soit comme une matrice, nous pouvons appliquer des opérations mathématiques usuelles, comme l’addition. Ainsi, nous parlons de bruit additif lorsque l’image bruitée est la somme de l’image originale et du bruit.
Un exemple très classique du bruit additif est le bruit gaussien, pour lequel les intensités sont choisies aléatoirement selon une loi normale.
Filtrer une image
Le filtrage constitue un volet important en traitement d’images, et un de ses objectifs principaux est de nettoyer l’image en éliminant le plus de bruit possible. Dans ce chapitre, nous allons nous intéresser davantage à cette classe de méthodes, et en particulier à la notion de filtre linéaire.
Les filtres linéaires
Il existe différentes techniques de filtrage selon le type de bruit à atténuer. Le lissage par moyennage utilise un filtre linéaire et fait partie, en ce sens, de la classe de filtrage la plus simple.
En traitement d’images, et même plus généralement en traitement du signal, un filtre linéaire est un système qui transforme une image en utilisant un opérateur linéaire. Il s’agit généralement d’un traitement local.
Une propriété importante d’un filtre linéaire est l’invariance par translation : la modification d’un pixel dépend de son voisinage, et non de sa position dans l’image.
Le lissage par moyennage utilise bien un filtre linéaire, appelé filtre moyenneur. En effet, l’opération appliquée à l’image initiale de représentation matricielle X pour obtenir l’image débruitée Y est composée d’additions et d’une division.
L’opérateur de convolution
Un filtre linéaire remplace la valeur de chaque pixel en entrée par une combinaison linéaire des intensités de ses pixels voisins. L’opérateur permettant d’effectuer cette transformation est appelé produit de convolution. C’est pourquoi l’application d’un filtre linéaire est également connue sous le terme de filtrage par convolution.
En notant \(\ast\) l’opérateur de convolution, la relation mathématique entre l’image initiale X et l’image filtrée Y pour tout type de filtre linéaire s’écrit \(Y=H\ast X \). Cela revient à modifier la valeur de chaque pixel de la manière suivante :
\(Y_{ij} = \sum \limits_{u=_k}^k \sum \limits_{v = -k}^k H_{u,v} X_{i-u, j-v}\)
\(H\) est le noyau de convolution : il s’agit d’une matrice carrée de taille impaire qui cractérise le filtre linéaire appliqué.
Pour les bords de l’image, nous appliquons une convolution partielle avec les pixels voisins disponibles. Dans tous les cas, il est préférable de ne pas réduire la taille de l’image.
Détecter et décrire efficacement les zones d’intérêts dans une image
Si vous tapez « Tour Eiffel » dans votre moteur de recherche d’images préféré, vous constaterez que les résultats représentent la même scène, mais de manières différentes. Beaucoup d’éléments peuvent varier d’une photo à une autre :
- La prise de vue (résultat d’une transformation affine ou d’une projection)
- L’orientation (résultat d’une rotation)
- L’échelle (résultat d’un zoom)
- Les propriétés photométriques : la luminosité et/ou le contraste (variations dues aux moments différents de la journée, météo, flash…)
- Occlusion : une partie de l’image est cachée
- Background clutter : une partie de l’image se confond avec les éléments en arrière-plan
Notion de point d’intérêts
Dans la première partie de ce cours, nous avions étudié différentes techniques permettant de transformer une image en une autre. Parmi elles, il y avait les transformations géométriques, qui modifient la position des pixels, et les manipulations d’histogrammes, qui corrigent la luminosité et le contraste.
Deux images d’une même classe, c’est-à-dire qui représentent la même chose, sont donc liées par une transformation. Cependant, la caractérisation précise de cette transformation nous est inconnue.
Comment déterminer la transformation qui permet de passer d’une image à une autre ?
Il s’agit en fait d’un problème classique en vision par ordinateur, appelé image matching. Les applications sont nombreuses : parmi elles, la création de panoramas, la détection d’images similaires à une autre (visual search), ou encore la reconnaissance d’objets dans une image (object recognition).
Au lieu de chercher à déterminer l’équation mathématique précise de la transformation comme dans la partie précédente, la stratégie consiste à trouver les éléments communs aux deux images. La problématique est alors reformulée ainsi :
Quels sont les éléments caractéristiques de l’image 1 ? Les retrouve-t-on dans l’image 2 ?
Cette tâche est plus ou moins triviale pour notre cerveau, mais difficile pour un ordinateur : celui-ci doit parvenir à décrire la particularité d’une classe d’images, et ce, en dépit de toutes les variations possibles listées plus haut.
Le template matching avec les filtres
Dans la partie précédente, nous avons découvert les filtres comme des outils capables de réduire le bruit dans une image. En fait, les filtres sont également souvent utilisés pour retrouver des motifs particuliers dans une image. Ces motifs sont représentés par de petites images, appelées templates. La tâche de template matching a pour but de retrouver des templates dans une image.
Le template matching réalisé avec des filtres utilise l’opérateur de corrélation croisée (cross-correlation), noté \(\otimes\) . Cet opérateur transforme l’image de représentation matricielle X en une nouvelle image Y de la façon suivante :
\(Y_{ij} = \sum \limits_{u = -k}^k \sum \limits_{v = -k}^k H_{u,v} X_{i+u, j+v}\)
Dans ce contexte, H est une petite image représentant le template à retrouver. Concrètement, cette opération revient à faire glisser H sur l’image X, à multiplier les pixels qui se superposent et à sommer ces produits.
Ainsi, le template matching consiste à calculer la corrélation croisée entre une image X et un filtre dont le noyau H représente un template que l’on souhaite retrouver dans X.
La nouvelle image Y, appelée carte de corrélation, nous indique où le template a été détecté : plus une région est claire (d’intensités élevées), plus elle ressemble au template recherché.
Les features, ou zones d’intérêt d’une image
En vision par ordinateur, le terme de (local) features désigne des zones intéressantes de l’image numérique. Ces zones peuvent correspondre à des contours, des points ou des régions d’intérêt. A chaque feature détectée est associé un vecteur, appelé descripteur (feature descriptor ou feature vector), qui, comme son nom l’indique, décrit la zone concernée.
La résolution du problème d’image matching se fait alors en deux étapes :
- Détecter et décrire les features dans chaque image
- Trouver les paires de features qui se correspondent dans les deux images (features matching)

L’algorithme d’image matching étudie des images caractérisées par leurs features, donc la qualité des résultats dépend (entre autres) de la pertinence des features détectées. En ce sens, la première étape est fondamentale et ne doit en aucun cas être négligée.
Un mauvais choix de features peut entraîner plusieurs difficultés dans l’étape de matching features :
- Problème 1 : deux images n’ont pas les mêmes features alors qu’elles représentent la même chose de manières différentes
- Problème 2 : ces deux images présentent les mêmes features, mais trouver les paires qui se correspondent est très difficile
Ces deux problèmes rendent le matching impossible et doivent donc être anticipés dès la première étape, lors de la détection et la description de features. Cela nous amène à la question suivante : quelles features faut-il sélectionner ?
- Répétable : une feature doit se retrouver dans les images représentant la même scène malgré les différences géométriques et photométriques. Une feature doit donc présenter des propriétés d’invariance à ces transformations.
- Distinctive : une feature doit être suffisamment unique et non ambiguë au sein d’une image pour faciliter le matching. Ce sont les informations contenues dans son descripteur qui doit mettre en valeur sa particularité.
- Locale : une feature doit correspondre à une zone suffisamment petite, et elle est décrite selon son voisinage uniquement. Cela permet d’éviter les difficultés de matching dues aux phénomènes d’occlusion et de background clutter.
En résumé, une bonne feature doit être suffisamment unique pour pouvoir différencier deux classes d’images différentes, et suffisamment générique pour pouvoir reconnaître facilement les images d’une même classe malgré la diversité des représentations.
Détection des coins et des bords d’une images
Dans ce chapitre, nous expliquerons deux méthodes couramment utilisées pour détecter des features classiques : le filtre de Canny pour les bords, puis le détecteur de Harris-Stephens pour les coins. Pour cela, nous devons dans un premier temps étudier la notion de gradient d’une image.
La détection des bords avec le filtre Canny
Les bords ou contours (edges en anglais) fournissent beaucoup d’information à propos d’une image : ils délimitent les objets présents dans la scène représentée, les ombres ou encore les différentes textures.
Un moyen pour détecter les bords serait de segmenter l’image en objets, mais il s’agit d’un problème difficile. Le filtre de Canny développé en 1986 est une solution plus simple, qui repose sur l’étude du gradient.
Les bords se situent dans les régions de l’image qui présentent de forts changements. En effet, les contours des objets correspondent à des changements de profondeur (on passe d’un objet à un autre situé en arrière-plan), et les ombres et différentes textures à des changements d’illumination.
Mathématiquement, la détection des bords revient donc à chercher les points de l’image où la fonction d’intensité II varie brusquement. Or, nous savons qu’une amplitude du gradient élevée indique un fort changement d’intensité. Le but est de chercher les maxima locaux de \(||\nabla I||\).
La méthode de détection des bords par le filtre de Canny comporte quatre étapes :
Etape 1. Réduction du bruit
Le bruit de l’image peut nous induire en erreur : les pixels aux valeurs aberrantes provoquent des forts changements d’intensité alors qu’ils n’appartiennent à aucun contour.
L’image doit donc être débruitée au préalable avec un filtre adapté. Comme étudié dans la première partie du cours, on utilisera un filtre gaussien pour éliminer le bruit additif, et un filtre médian pour le « poivre et sel » (très rare).
Etape 2. Calcul du gradient de l’image
Le gradient de l’image débruitée est approximé par filtrage de convolution, le plus souvent avec les masques de Sobel.
Nous calculons ensuite l’amplitude et la direction du gradient en tout point de l’image
Les bords sont repérés par les points de forte amplitude.
Etape 3. Suppression des non-maxima
Les bords trouvés à l’étape précédente sont trop épais. Pour les rendre plus précis, nous ne sélectionnons que les points pour lesquels l’amplitude du gradient est localement maximale dans sa direction.
Pour cela, on quantifie Θ et on trouve les deux voisins de chaque pixel en suivant la direction de son gradient.
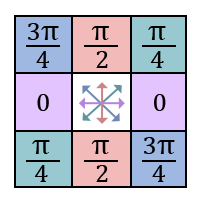
Le pixel courant est retenu que si son amplitude est plus grande que celles de ses deux voisins.
Etape 4. Seuillage
Parmi les points sélectionnés dans l’étape précédente, nous ne retenons finalement que ceux dont l’amplitude du gradient est supérieure à un certain seuil.
Il est difficile de choisir la valeur d’un « bon » seuil. C’est pourquoi on privilégie le seuillage par hystérésis, qui utilise deux seuils, notés \(s_{bas}\) et \(s_{haut}\)
Ce détecteur est facile à mettre en oeuvre, mais présente deux limitations majeures :
- Le choix des paramètres (variance du filtre gaussien et les deux seuils). Ils ont un impact très important sur le temps de calcul et la qualité des résultats, mais il n’existe pas de méthode automatique pour déterminer les meilleures valeurs pour chaque image…
- Les bords détectés sont des points et pas des courbes, et il est difficile de « chaîner » les points.
La localisation des coins avec le détecteur de Harris-Stephens
Les coins (corners en anglais) sont d’autres features riches en informations. Ils se situent dans les régions où l’intensité varie fortement dans au moins deux directions :

Le détecteur de Harris-Stephens, développé en 1988, est une technique très populaire permettant de repérer les coins dans une image. Il est basé sur le détecteur de Moravec, qui exploite le gradient.
Le détecteur de Moravec permet de déterminer les changements d’intensité autour d’un pixel donné.
L’idée est de considérer un voisinage centré en ce pixel de le décaler légèrement dans plusieurs directions, puis de calculer pour chaque déplacement la variation d’intensité. Cela se traduit mathématiquement par la fonction suivante :
\(E_{m,n}(u,v) = \sum\limits_{(x,y) \in W_{m,n}} [I(x+u, y+v) – I(x,y)]^2\)
Nous appliquons cette fonction dans les trois situations principales ci-dessous :
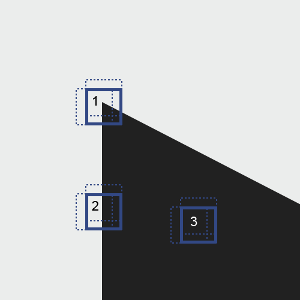
Situation 1 : la zone contient un coin, l’intensité change brusquement dans plusieurs directions, donc la fonction E prend de fortes valeurs dans ces directions
Situation 2 : la zone contient un contour, l’intensité change brusquement si on se déplace horizontalement et très peu verticalement. Ainsi, E prend de fortes valeurs si on déplace perpendiculairement au contour, et des faibles pour des déplacements le long du contour.
Situation 3 : pas de changement d’intensité : la région est uniforme. E prend alors de faibles valeurs dans toutes les directions
Le pixel \((m,n)\) correspond à un coin si la plus petite variation d’intensité autour de lui est maximale par rapport à celle des autres pixels.
Le détecteur de Harris-Stephens est une amélioration du détecteur de Moravec. Il apporte trois modifications majeures :
- La fenêtre carrée \(W_{m,n}\) centrée en \((m,n)\) est remplacée par une fenêtre gaussienne.
- \(I(x+u, y+v)\) est approximé par un développement de Taylor au voisinage de \((x,y)\)
- Les coins sont détectés selon un nouveau critère : les valeurs propres $\latex \lambda_1$ et $\latex \lambda_2$ de $M$
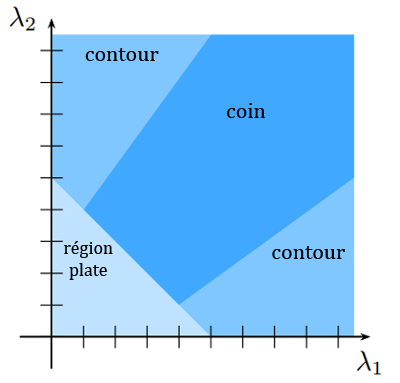
Trouver les valeurs propres de M peut être fastidieux. Une alternative consiste alors à analyser les valeurs de l’opérateur R : \(R = det(M) – k.trace(M)^2\) avec \(k\) une constante choisie entre 0.04 et 0.06
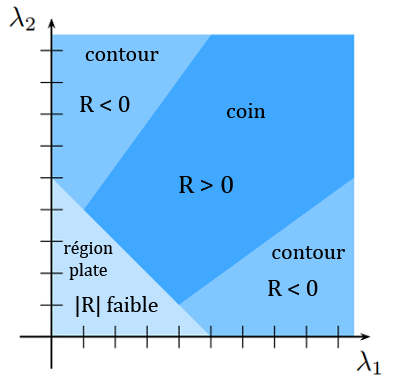
La détection des coins avec le détecteur de Harris-Stephens se fait donc en quatre étapes :
Etape 1. Calcul de la matrice M pour chaque pixel. Les dérivées partielles sont approximées en filtrant l’image par convolution avec les masques de Sobel
Etape 2. Calcul de R pour chaque pixel
Etape 3. Seuillage de R. On sélectionne les pixels pour lesquels \(R>s\) , où s est un seuil à choisir
Etape 4. Suppression des non-maxima de R. Les coins correspondent aux maxima locaux de R : pour les trouver, on applique aux pixels sélectionnés la méthode décrite dans l’étape 3 du filtre de Canny
Utiliser les points d’intérêts pour classifier une image
La classification d’images est un problème fondamental en vision par ordinateur, qui a de nombreuses applications concrètes. Le but est de construire un système capable d’assigner correctement une catégorie à n’importe quelle image en entrée. Un tel système exploite des algorithmes de Machine Learning issus de l’apprentissage supervisé.
La méthode de résolution
Le problème de classification d’images est posé formellement de la manière suivante :
- Il y a K classes d’images possibles. L’ensemble \({0,1,…,K−1}\) définit les labels des différentes classes (exemple : 0 = « oiseau » et 1 = « chien »)
- Nous avons une collection de N images en entrée : \({X_i}_{i \in {1,…,N}}\)
- Les classes des N images sont connues à l’avance : chaque image Xi est étiquetée par \(y_i \in {0,1,…,K−1}\)
- Le but est de classifier correctement une nouvelle image, dont on ne connaît pas la classe : on veut trouver la bonne étiquette y′ de X′
Le schéma ci-dessous illustre la méthode utilisée pour résoudre ce problème :
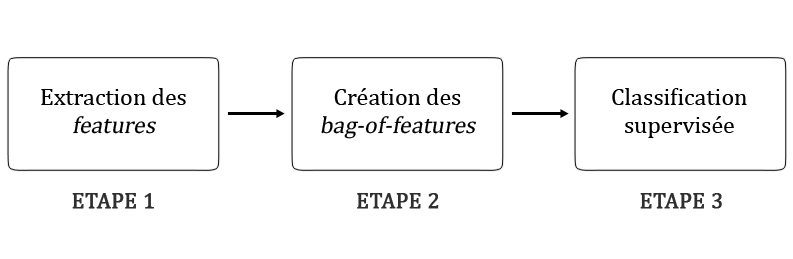
Création des bag-of-features
Comme son nom l’indique, un bag-of-features représente une image par un « sac » dans lequel on a mis ses features en vrac. Mathématiquement, c’est un vecteur créé en deux temps : d’abord, on crée les « visual words », puis on construit un histogramme.
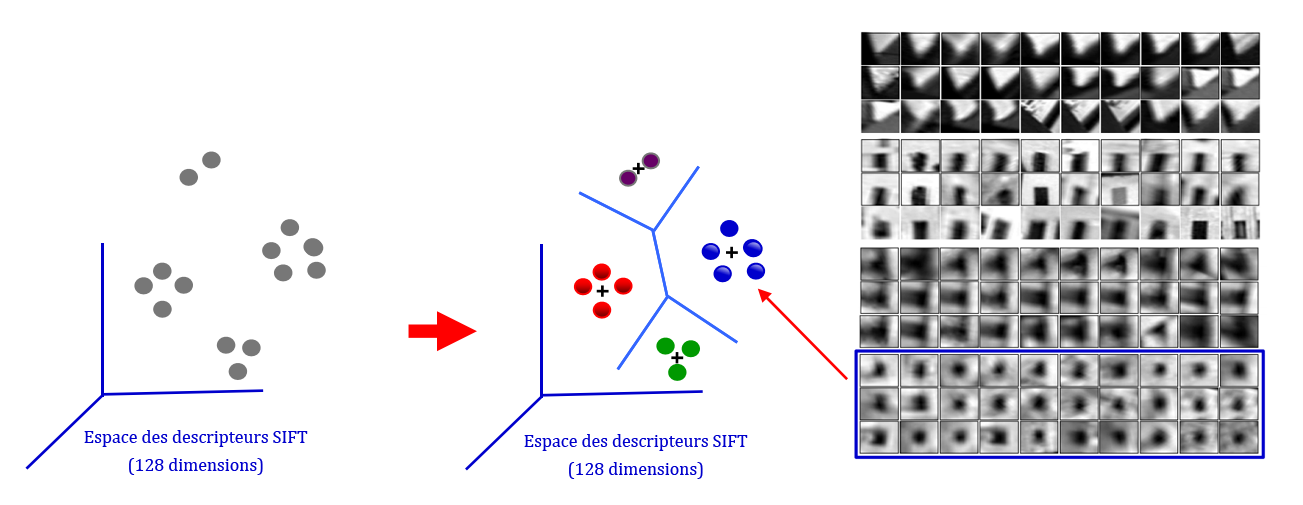
Création des visual words
Le bag-of-words caractérise un document textuel par les mots qu’il a utilisés. Ici, les images sont caractérisées par les features trouvées lors de l’étape 1.
Néanmoins, s’il est possible de retrouver plusieurs mots strictement identiques dans deux documents, ce n’est pas le cas pour les images et les features. En effet, le critère de répétabilité nous dit qu’une feature peut se retrouver dans plusieurs images, mais les features sont toutes différentes lorsqu’on les compare pixel par pixel. Cela s’explique par les variations géométriques, photométriques, ou mêmes dues aux apparences différentes d’un objet d’une classe (exemple : il y a plusieurs types d’oiseaux).
Ainsi, on obtient beaucoup de features, mais certaines représentent un même élément de façons différentes. Ces éléments qui se déclinent en plusieurs versions sont appelées des visual words. par analogie avec les données textuelles : les textes sont caractérisés par des mots, et les images par des mots visuels.

Pour créer le « dictionnaire » de visual words, il suffit d’appliquer un algorithme de clustering aux descripteurs de features construits à l’étape 1, comme le k-means. Les visual words correspondent alors aux centres des clusters trouvés.
Construction de l’histogramme
Il reste à décrire les images en fonction de ces visual words. Pour chaque image, on crée un histogramme qui indique la fréquence d’apparition de chaque visual word dans l’image :
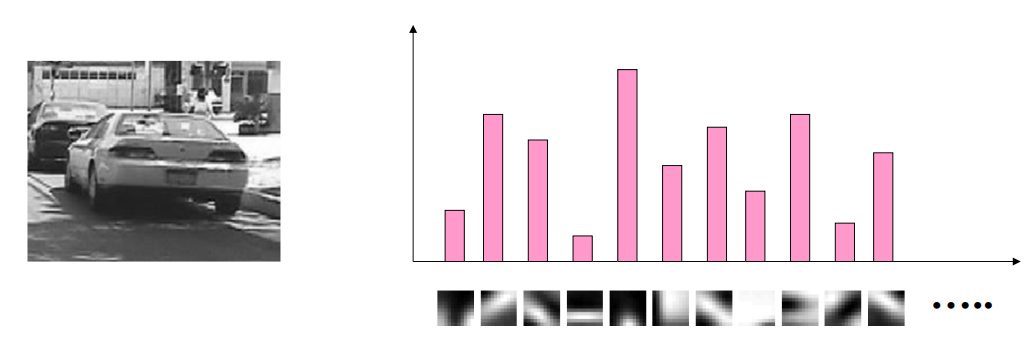
Finalement, le bag-of-features d’une image est le vecteur dans lequel on a stocké les valeurs de l’histogramme et qu’on a normalisé (en divisant par la norme euclidienne).
Classification supervisée
C’est la dernière étape de notre méthode de résolution : l’objectif est d’apprendre les règles de décision permettant d’assigner correctement une représentation bag-of-features à une classe. Cela signifie qu’on va entraîner un algorithme d’apprentissage supervisé sur les bag-of-features construits à l’étape 2.
Classifier des images à l’aide de réseaux de neurones convolutifs
Dans la partie précédente, nous avons étudié la notion de features en vision et les méthodes traditionnellement utilisées pour faire de la classification d’images. Celles-ci consistent à extraire les features de chaque image du jeu de données, puis à entraîner un classifieur sur ces features.
Ces techniques d’apprentissage supervisé peuvent fournir de très bons résultats et leur performance dépend fortement de la qualité des features préalablement trouvée. Il existe plusieurs méthodes d’extraction et de description de features. L’algorithme SIFT est très populaire, puisqu’il parvient à détecter et à décrire efficacement des features pertinentes.
En pratique, l’erreur de classification n’est jamais nulle. Les résultats peuvent alors être améliorés en créant de nouvelles méthodes d’extraction de features, plus adaptées aux images étudiées, ou en utilisant un « meilleur » classifieur.
Mais en 2012, une révolution se produit : lors de la compétition annuelle de vision par ordinateur ILSVRC, un nouvel algorithme de Deep Learning explose les records ! Il s’agit d’un réseau de neurones convolutif appelé AlexNet.
Définition d’un réseau de neurones convolutif
Les réseaux de neurones convolutifs ont une méthodologie similaire à celle des méthodes traditionnelles d’apprentissage supervisé : ils reçoivent des images en entrée, détectent les features de chacune d’entre elles, puis entraînent un classifieur dessus.
Cependant, les features sont apprises automatiquement ! Les CNN réalisent eux-mêmes tout le boulot fastidieux d’extraction et description de features : lors de la phase d’entraînement, l’erreur de classification est minimisée afin d’optimiser les paramètres du classifieur ET les features ! De plus, l’architecture spécifique du réseau permet d’extraire des features de différentes complexités, des plus simples au plus sophistiquées. L’extraction et la hiérarchisation automatiques des features, qui s’adaptent au problème donné, constituent une des forces des réseaux de neurones convolutifs : plus besoin d’implémenter un algorithme d’extraction « à la main », comme SIFT ou Harris-Stephens.
Contrairement aux techniques d’apprentissage supervisé, les réseaux de neurones convolutifs apprennent les features de chaque image. C’est là que réside leur force : les réseaux font tout le boulot d’extraction de features automatiquement, contrairement aux techniques d’apprentissage
Aujourd’hui, les réseaux de neurones convolutifs, aussi appelés CNN ou ConvNet pour Convolutional Neural Network, sont toujours les modèles les plus performants pour la classification d’images. Cette partie leur est donc naturellement consacrée.
Rappel sur les réseaux de neurones
Pour bien comprendre les réseaux de neurones convolutifs, il est important de connaître les bases des réseaux de neurones
Les principaux éléments à retenir sont les suivants :
- Un réseau de neurones est un système composé de neurones, généralement répartis en plusieurs couches connectées entre elles
- Un tel système s’utilise pour résoudre divers problèmes statistiques, mais nous nous intéressons ici qu’au problème de classification (très courant). Dans ce cas, le réseau calcule à partir de l’entrée un score (ou probabilité) pour chaque classe. La classe attribuée à l’objet en entrée correspond à celle de score le plus élevé
- Chaque couche reçoit en entrée des données et les renvoie transformées. Pour cela, elle calcule une combinaison linéaire puis applique éventuellement une fonction non-linéaire, appelée fonction d’activation. Les coefficients de la combinaison linéaire définissent les paramètres (ou poids) de la couche
- Un réseau de neurones est construit en empilant les couches : la sortie d’une couche correspond à l’entrée de la suivante.
- Cet empilement de couches définit la sortie finale du réseau comme le résultat d’une fonction différentiable de l’entrée
- La dernière couche calcule les probabilités finales en utilisant pour fonction d’activation la fonction logistique (classification binaire) ou la fonction softmax (classification multi-classes)
- Une fonction de perte (loss function) est associée à la couche finale pour calculer l’erreur de classification. Il s’agit en général de l’entropie croisée
- Les valeurs des poids des couches sont apprises par rétropropagation du gradient : on calcule progressivement (pour chaque couche, en partant de la fin du réseau) les paramètres qui minimisent la fonction de perte régularisée. L’optimisation se fait avec une descente du gradient stochastique
Les réseaux de neurones convolutifs
Quelle est la différence entre un réseau de neurones et un réseau de neurones convolutif ?
Les réseaux de neurones convolutifs désignent une sous-catégorie de réseaux de neurones : ils présentent donc toutes les caractéristiques listées ci-dessus. Cependant, les CNN sont spécialement conçus pour traiter des images en entrée. Leur architecture est alors plus spécifique : elle est composée de deux blocs principaux.
Le premier bloc fait la particularité de ce type de réseaux de neurones, puisqu’il fonctionne comme un extracteur de features. Pour cela, il effectue du template matching en appliquant des opérations de filtrage par convolution. La première couche filtre l’image avec plusieurs noyaux de convolution, et renvoie des « feature maps », qui sont ensuite normalisées (avec une fonction d’activation) et/ou redimensionnées.
Ce procédé peut être réitéré plusieurs fois : on filtre les features maps obtenues avec de nouveaux noyaux, ce qui nous donne de nouvelles features maps à normaliser et redimensionner, et qu’on peut filtrer à nouveau, et ainsi de suite. Finalement, les valeurs des dernières feature maps sont concaténées dans un vecteur. Ce vecteur définit la sortie du premier bloc, et l’entrée du second.
Le second bloc n’est pas caractéristique d’un CNN : il se retrouve en fait à la fin de tous les réseaux de neurones utilisés pour la classification. Les valeurs du vecteur en entrée sont transformées (avec plusieurs combinaisons linéaires et fonctions d’activation) pour renvoyer un nouveau vecteur en sortie. Ce dernier vecteur contient autant d’éléments qu’il y a de classes : l’élément ii représente la probabilité que l’image appartienne à la classe ii. Chaque élément est donc compris entre 0 et 1, et la somme de tous vaut 1. Ces probabilités sont calculées par la dernière couche de ce bloc (et donc du réseau), qui utilise une fonction logistique (classification binaire) ou une fonction softmax (classification multi-classe) comme fonction d’activation.
Comme pour les réseaux de neurones ordinaires, les paramètres des couches sont déterminés par rétropropagation du gradient : l’entropie croisée est minimisée lors de la phase d’entraînement. Mais dans le cas des CNN, ces paramètres désignent en particulier les features des images.
Les différents types de couches d’un CNN sont expliquées dans le chapitre suivant.
Découvrir les différentes couches d’un CNN
Il existe quatre types de couches pour un réseau de neurones convolutif : la couche de convolution, la couche de pooling, la couche de correction ReLU et la couche fully-connected. Dans ce chapitre, je vais vous expliquer le fonctionnement de ces différentes couches.
La couche de convolution
La couche de convolution est la composante clé des réseaux de neurones convolutifs, et constitue toujours au moins leur première couche.
Son but est de repérer la présence d’un ensemble de features dans les images reçues en entrée. Pour cela, on réalise un filtrage par convolution : le principe est de faire « glisser » une fenêtre représentant la feature sur l’image, et de calculer le produit de convolution entre la feature et chaque portion de l’image balayée. Une feature est alors vue comme un filtre : les deux termes sont équivalents dans ce contexte.
Cette technique est très proche de celle étudiée dans la partie précédente pour faire du template matching : ici, c’est le produit convolution qui est calculé, et non la corrélation croisée.
La couche de convolution reçoit donc en entrée plusieurs images, et calcule la convolution de chacune d’entre elles avec chaque filtre. Les filtres correspondent exactement aux features que l’on souhaite retrouver dans les images.
On obtient pour chaque paire (image, filtre) une carte d’activation, ou feature map, qui nous indique où se situent les features dans l’image : plus la valeur est élevée, plus l’endroit correspondant dans l’image ressemble à la feature.
Comment choisir les features ?
Contrairement aux méthodes traditionnelles, les features ne sont pas pré-définies selon un formalisme particulier (par exemple SIFT), mais apprises par le réseau lors la phase d’entraînement ! Les noyaux des filtres désignent les poids de la couche de convolution. Ils sont initialisés puis mis à jour par rétropropagation du gradient.
C’est là toute la force des réseaux de neurones convolutifs : ceux-ci sont capables de déterminer tout seul les éléments discriminants d’une image, en s’adaptant au problème posé. Par exemple, si la question est de distinguer les chats des chiens, les features automatiquement définies peuvent décrire la forme des oreilles ou des pattes.
La couche de pooling
Ce type de couche est souvent placé entre deux couches de convolution : elle reçoit en entrée plusieurs feature maps, et applique à chacune d’entre elles l’opération de pooling.
L’opération de pooling consiste à réduire la taille des images, tout en préservant leurs caractéristiques importantes.
Pour cela, on découpe l’image en cellules régulières, puis on garde au sein de chaque cellule la valeur maximale. En pratique, on utilise souvent des cellules carrées de petite taille pour ne pas perdre trop d’informations. Les choix les plus communs sont des cellules adjacentes de taille 2 ×× 2 pixels qui ne se chevauchent pas, ou des cellules de taille 3 ×× 3 pixels, distantes les unes des autres d’un pas de 2 pixels (qui se chevauchent donc).
On obtient en sortie le même nombre de feature maps qu’en entrée, mais celles-ci sont bien plus petites.
La couche de pooling permet de réduire le nombre de paramètres et de calculs dans le réseau. On améliore ainsi l’efficacité du réseau et on évite le sur-apprentissage.
Les valeurs maximales sont repérées de manière moins exacte dans les feature maps obtenues après pooling que dans celles reçues en entrée – c’est en fait un grand avantage ! En effet, lorsqu’on veut reconnaître un chien par exemple, ses oreilles n’ont pas besoin d’être localisées le plus précisément possible : savoir qu’elles se situent à peu près à côté de la tête suffit !
Ainsi, la couche de pooling rend le réseau moins sensible à la position des features : le fait qu’une feature se situe un peu plus en haut ou en bas, ou même qu’elle ait une orientation légèrement différente ne devrait pas provoquer un changement radical dans la classification de l’image.
La couche de correction ReLU
ReLU (Rectified Linear Units) désigne la fonction réelle non-linéaire définie par ReLU(x)=max(0,x)ReLU(x)=max(0,x).
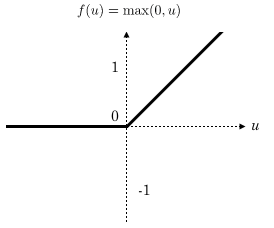
La couche de correction ReLU remplace donc toutes les valeurs négatives reçues en entrées par des zéros. Elle joue le rôle de fonction d’activation.
La couche fully-connected
La couche fully-connected constitue toujours la dernière couche d’un réseau de neurones, convolutif ou non – elle n’est donc pas caractéristique d’un CNN.
Ce type de couche reçoit un vecteur en entrée et produit un nouveau vecteur en sortie. Pour cela, elle applique une combinaison linéaire puis éventuellement une fonction d’activation aux valeurs reçues en entrée.
La dernière couche fully-connected permet de classifier l’image en entrée du réseau : elle renvoie un vecteur de taille NN, où NN est le nombre de classes dans notre problème de classification d’images. Chaque élément du vecteur indique la probabilité pour l’image en entrée d’appartenir à une classe.
Par exemple, si le problème consiste à distinguer les chats des chiens, le vecteur final sera de taille 2 : le premier élément (respectivement, le deuxième) donne la probabilité d’appartenir à la classe « chat » (respectivement « chien »). Ainsi, le vecteur [0.90.1][0.90.1] signifie que l’image a 90% de chances de représenter un chat.
Chaque valeur du tableau en entrée « vote » en faveur d’une classe. Les votes n’ont pas tous la même importance : la couche leur accorde des poids qui dépendent de l’élément du tableau et de la classe.
Pour calculer les probabilités, la couche fully-connected multiplie donc chaque élément en entrée par un poids, fait la somme, puis applique une fonction d’activation (logistique si N=2N=2, softmax si N>2N>2) :
Ce traitement revient à multiplier le vecteur en entrée par la matrice contenant les poids. Le fait que chaque valeur en entrée soit connectée avec toutes les valeurs en sortie explique le terme fully-connected.
Comment connait-on la valeur de ces poids ?
Le réseau de neurones convolutif apprend les valeurs des poids de la même manière qu’il apprend les filtres de la couche de convolution : lors de phase d’entraînement, par rétropropagation du gradient.
La couche fully-connected détermine le lien entre la position des features dans l’image et une classe. En effet, le tableau en entrée étant le résultat de la couche précédente, il correspond à une carte d’activation pour une feature donnée : les valeurs élevées indiquent la localisation (plus ou moins précise selon le pooling) de cette feature dans l’image. Si la localisation d’une feature à un certain endroit de l’image est caractéristique d’une certaine classe, alors on accorde un poids important à la valeur correspondante dans le tableau.